vivo pulsar万亿级消息处理实践 数据发送原理解析、性能调优与存储服务支撑
在当今大数据与实时计算的浪潮下,消息队列作为系统解耦、流量削峰和异步通信的核心组件,其处理能力直接关系到企业数据平台的稳定与效率。vivo基于Apache Pulsar构建了支撑万亿级消息流转的处理平台,本文将深入解析其数据发送的核心原理、关键性能调优策略以及底层数据处理与存储服务的支撑体系。
一、 数据发送原理解析:从客户端到Broker的旅程
vivo Pulsar平台的数据发送流程,是一个高效、可靠的分布式过程。其核心基于Pulsar的“发布-订阅”模型,并针对生产环境进行了深度优化。
- 生产者客户端工作机制:生产者(Producer)与Pulsar集群中的某个Broker建立TCP长连接。消息并非直接发送给最终的存储节点,而是先发送给一个负责该Topic的Broker(Leader Broker)。客户端内置了负载均衡与故障转移机制,能自动发现并切换至健康的Broker。在发送前,消息会在客户端进行批量(Batching)聚合,并支持异步发送、内存队列缓存等机制,极大提升了吞吐量。
- Broker层的处理与分发:接收消息的Broker充当了无状态的路由层。它首先验证生产者的权限和Topic的配置,随后将消息写入一个高性能的持久化写入缓冲区(Managed Ledger的写缓存)。几乎Broker会立即将消息分发给所有已连接的消费者(Readers),实现低延迟的推送。持久化操作则由后台线程异步完成,实现了写入路径与持久化路径的解耦,这是Pulsar高吞吐的关键设计之一。
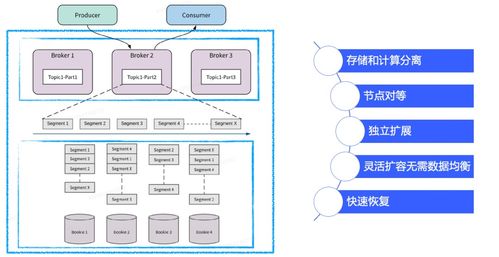
- BookKeeper的持久化存储:Broker将消息的持久化任务委托给Apache BookKeeper。BookKeeper是一个专为日志流存储设计的分布式存储系统。它将一个Topic分区(Ledger)的数据条带化(Striping)写入多个物理Bookie节点,既保证了数据的高可用与强一致性(通过Quorum写入协议),又通过并行I/O提升了写入性能。这种存储与计算分离的架构,使得Broker可以轻松水平扩展,而存储层独立扩展。
二、 性能调优实践:通往万亿级处理能力的关键
面对海量消息场景,vivo团队从多个维度对Pulsar集群进行了系统性调优。
- 生产者端调优:
- 批量发送(Batching):合理调整
batchingMaxMessages、batchingMaxPublishDelay参数,在吞吐量与延迟之间取得最佳平衡。对于高吞吐场景,增大批量大小;对于低延迟场景,则减小批量或关闭批量。
- 压缩(Compression):启用Snappy或ZSTD等压缩算法,显著减少网络传输与存储成本,提升有效吞吐。
- 异步与队列:采用异步发送模式,并适当调大生产者队列大小(
maxPendingMessages),以应对瞬间流量高峰,避免生产者阻塞。
- Broker与BookKeeper调优:
- 资源分配:确保Broker拥有充足的堆内外内存。增大Managed Ledger的读写缓存大小,减少与BookKeeper的磁盘交互频率。
- Bookie磁盘优化:为Bookie节点配置多磁盘目录(journal磁盘与ledger磁盘分离),使用高性能SSD,并优化操作系统I/O调度参数(如使用deadline/noop调度器),最大化磁盘IOPS与吞吐。
- 网络与GC优化:优化Linux内核网络参数(如TCP缓冲区大小),并针对JVM垃圾回收器(如G1 GC)进行精细化调参,减少GC停顿对高并发读写的影响。
- 架构层面优化:
- 分层存储(Tiered Storage):将冷数据从昂贵的BookKeeper存储自动卸载到对象存储(如S3、OSS),大幅降低长期存储成本,同时保持对历史数据的透明访问能力。
- 地理复制(Geo-Replication):跨地域部署集群并配置异步复制,在保障数据容灾与异地就近消费的不对原始集群的写入性能造成显著影响。
三、 数据处理与存储支持服务:生态与稳定性基石
万亿级消息流的顺畅处理,离不开周边数据处理与强大的存储服务支撑。
- 实时计算集成:vivo将Pulsar与Flink、Spark Streaming等流计算引擎深度集成。Pulsar提供了精确一次(Exactly-Once)语义保障、按时间戳回溯读取(Message Retention & TTL)等特性,使得实时计算作业能可靠、灵活地处理消息流,支撑实时风控、用户行为分析等关键业务。
- 统一的消息存储服务:Pulsar的“流”与“队列”统一模型,使得一套系统能同时支持传统队列场景和持久化日志流场景。其无限Topic分区能力和分层存储,为业务提供了近乎无限的、成本可控的消息存储能力,成为公司级的数据流通总线。
- 监控与运维支撑体系:
- 全方位监控:构建了涵盖Broker/Bookie节点资源(CPU、内存、磁盘IO、网络)、JVM状态、消息堆积、端到端延迟等指标的立体监控告警体系。
- 自动化运维:针对Topic的自动扩缩容、基于预测的容量规划、故障节点的自动隔离与恢复等,开发了自动化运维平台,保障了集群的长期稳定运行和高可用性。
- Schema Registry:集成Schema Registry服务,对消息格式进行集中管理和演进控制,保障了上下游系统数据格式的一致性,减少了数据解析错误。
###
vivo在Pulsar万亿级消息处理上的实践表明,通过深入理解其“存储计算分离”和“分层架构”的核心设计,结合从客户端到服务端、从硬件到软件的全链路系统性调优,并构建完善的数据生态与运维支撑体系,Apache Pulsar完全有能力胜任超大规模、超高可用的企业级消息平台角色。这一实践不仅保障了vivo内部业务的流畅运行,也为业界提供了可借鉴的、经过生产环境验证的大型消息平台建设方案。
如若转载,请注明出处:http://www.520hbwl.com/product/46.html
更新时间:2026-02-25 09:15:02